AIでホール攻略
お世話になっております、スログラミングです。
タイトルにもあるとおり、今回はAIに関するプログラムを作ろうと思っていますが、最近のAI技術ってすごいですよね。
例えば、Googleがドアホンを出してるって知ってますか?
「Google Nest Doorbell」っていうんですけど、「スマートウォッチ」とかならまだイメージが湧くと思いますが、「スマートドアベル」って何ができるの?って思いますよね。
ちょっと調べたところによると、インターホン鳴らされると映像が映るのは普通のドアホンと同じなんですが、Google Nest Doorbellは映像と一緒に「誰が何のために来たのか?」っていう情報まで表示してくれるらしいんですよ。
いやいや、すごっ!
どうやら顔認識で人物を特定しつつ、その人の持ち物等を認識することで何のために来たのか?を理解してるらしいですね。
(例えば、「この人来たときは箱持ってたのに、帰るときは箱持ってなかった。」→「あ、もしかして配達員さん?」みたいな感じで。)
こんな感じで知らない内に色んなところにAIが導入されてきているんですが、どうやらパチンコ業界も例外ではないらしく、最近はスロットの設定配分をAIが決めてくれるような機能があるらしいです。
とするならば、こちらもAIで対抗するしかない!
目には目を。復讐には復讐を。AIにはAIを。(アンフェア懐かしい。)
※素人が自分なりの理解で書いた記事&お試しレベルのコーディングなので、暖かい目で見て下さい。
ということで、本日のアジェンダはこちら。
1. LightGBMとは
一口にAIといっても中身は色々あるようで、有名なのはディープラーニングですよね。
ディープラーニングといえば、↓図のような感じで、入力があって出力があって間にネットワークがたくさん張ってる感じのやつですね。

で、今回使うやつはディープラーニングとは違うやつです。
というのも、色々調べてたらKaggleっていうデータ分析のコンペ(賞金も出るらしい)があって、そこの上位者がよく使ってる手法があると!
これはもう使ってみるしかないでしょ!ってことで、使う手法がこちら!
「LightGBM(ライトジービーエム)」
「なんか難しそうな名前だけど、Lightってついてるからもしかしたら簡単かも?」って感じですが、Google先生で調べてみるとこう書いてあります。
「決定木アルゴリズムの勾配ブースティングフレームワーク」
はい・・・、さっぱりわかりませんね。
ちょっと一旦現実逃避させていただいて・・・。
私、普段はテレビ全く見ないんですけど、こないだ年末に実家に帰った時に久しぶりにテレビ見てて、年末特番でミルクボーイさんってコンビが漫才してたんですね。
その時見てたのが、オーバーオールってネタで、すごい面白いんですよ。
細かい言い回しは忘れてしまいましたが、ざっくりとした流れはこんな感じです。
駒場さん:あるものの名前がわからない。
内海さん:特徴言ってほしい。
駒場さん:こんな特徴(特徴1)。
内海さん:オーバーオールやないかい。
駒場さん:こんな特徴(特徴2)。
内海さん:ほな、オーバーオールと違うやないかい。
駒場さん:こんな特徴(特徴3)。
内海さん:オーバーオールやないかい。
・
・
・
(なんか凄くつまらなさそうになってしまったので、ぜひ実際の漫才を見ていただきたく。。)
で、これがLightGBMなんです。
そう、「LightGBM=ミルクボーイさんの漫才」です。
ちょっと補足すると、先ほどの流れを図にすると、こうなりますよね。
LightGBMは、こんな感じでたくさんのif文で分岐させていって欲しい結果を得る手法です。

2. LightGBMの使い方
LightGBMがやっていることのイメージはつかめたと思うので、ここから使い方を説明していきます。
LightGBMはいわゆる教師あり学習と呼ばれます。教師あり=あらかじめ特徴を教えておくってことですね。
先ほどの例で言うと、そもそも内海さんがオーバーオールの特徴を知っていないと、駒場さんがいくら特徴を言ったところで「オーバーオールか否か?」といった判断はできませんよね?
つまり、あらかじめ内海さん(=AI)にオーバーオールの特徴を教えておくのが教師あり学習です。
その上で、駒場さんが色んな特徴を言っていくことで、内海さんがオーバーオールか否かの判断をしてくれます。
図にするとこんな感じです。
オレンジ部分のデータベースを作成して、LightGBMで学習させれば良いということですね。

これで使い方のイメージはできたと思いますので、ここらへんでパチンコ・スロットの話に置き換えていきます。
狙い台の絞り方といえば、上げ狙いや据え置き狙い等ありますが、今回はシンプルに末尾狙いを例にしたいと思います。
具体的には、「日付の末尾と台番が同じなら設定6」のホールを想定します。
(7のつく日は台番末尾が7の台が設定6みたいな感じです。)
ということで、今回用意したデータベースはこちら。
(LightGBMは基本的には数値しか扱えないので、日付を「yyyy/mm/dd」でなく「yyyymmdd」で表記しています。)
(文字列を扱う方法ももちろんありますが、今回は使用しないので勉強してません。)
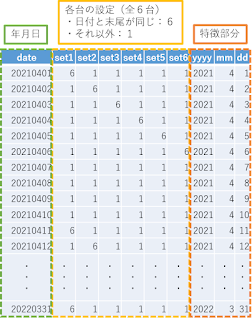
言わずもがな最も大事なのは、オレンジで囲った特徴部分です。
例えば、
「今日は2021年4月1日です。1番台の設定は?」
と聞かれるより、
「今日は1日です。1番台の設定は?」
と聞かれた方が答えに近づけそうな気がしますよね?
ここで、「1日」の部分は「特徴量」と言ったりします。
もちろんデータの規則性等を自動で見つけてくれるのが機械学習の良いところではありますが、人間側が有用な特徴量を抽出してAIに渡してあげることも精度向上には重要です。
3. Pythonでのコーディング
イメージしやすいように説明しようとしたら結構長くなってしまいましたが、これで一通り説明が終わったということで、ここから実際にPythonでコーディングしていきます。
3.1. データセットを作成
AIを使うにあたって、データセットというものを作成する必要があります。
といっても新たなデータベースをもう1個作るわけではなく、↓図のように先ほど作ったデータベースを訓練用とテスト用に分けるだけです。
(当然新たにデータベースを作成してもOKです。)
訓練データでトレーニングして、テストデータでトレーニングの成果をチェックする感じです。

Pythonでは、sklearnのtrain_test_splitを使えば簡単にやってくれます。
(名前もそのままですね。)
ちなみにコメントにも書いていますが、引数のstratifyは入れておいた方が良いと思います。
というのも、train_test_splitはデータベースをランダムで訓練用とテスト用にわけるわけですが、パチンコ屋さんでは設定1がほとんどだと思うので、ランダムでわけたテストデータに設定1のデータしかないみたいなことが起きてしまうわけです。
そうすると、AIさんはとりあえず設定1と答えておけば全問正解するわけで、正しい学習成果が得られなくなってしまいます。
それに対して、stratifyを使うことで、訓練データとテストデータの設定投入比率が一致するようにできるので、上述したような問題は発生しなくなります。
import pandas as pd
from sklearn.model_selection import train_test_split
# データベースファイルを読み込む
df = pd.read_csv("D:\Test/database.csv", encoding="shift-jis").fillna(0)
# 訓練データとテストデータに分割する(設定以外を使用して、設定を求める)
# set1=1番台の設定を求める。2番台~6番台の設定を求めたい場合はset2~set6に変更する。
X = df.drop(columns=['set1', 'set2', 'set3', 'set4', 'set5', 'set6'], inplace=False).values.astype('float')
y = df[['set1']].values.astype('float') - 1
# 普通にランダムにすると設定1のデータばかり集まる可能性があるので、stratifyで設定の割合を揃える。
X_train, X_test, Y_train, Y_test = train_test_split(X, y, test_size=0.2, random_state=0, stratify=y)
3.2. LightGBMで学習
ここで先ほど作成した訓練データとテストデータをAI(LightGBM)に放り投げていくんですが、細かいパラメータ(ハイパーパラメータといいます。)がたくさんあります。
全部説明するのは私の知識的に無理なので、1箇所だけさらっと説明します。
objectiveというパラメータですが、これはその名の通り目的を決めるパラメータです。
LightGBMではざっくりと3つのことができます。
まずは、回帰分析('objective': 'regression')。これは「明日の気温は何度ですか?」みたいに数値を求めたいときに使います。
次に、二値分類('objective': 'binary')。これは「明日は晴れですか?」みたいにYesorNoで答えられる場合に使えます。
最後に多クラス分類('objective': 'multiclass')。これは「明日は晴れor曇りor雨?」みたいに複数の答えがある場合に使えます。
スロットの設定を求めたいのであればmulticlass(設定1~6の6クラス)、パチンコの千円Sを求めたいのでregressionを使用すれば良いと思います。(スロットでも今回みたいに1or6ならbinaryでもOKですが。)
import lightgbm as lgb
# データセットを登録
lgb_train = lgb.Dataset(X_train, Y_train)
lgb_test = lgb.Dataset(X_test, Y_test, reference=lgb_train)
# LightGBMのハイパーパラメータを設定
params = {'task': 'train', # train(学習) or predict(予測)
'boosting_type': 'gbdt', # GBDT(決定木の勾配ブースティング)
'objective': 'multiclass', # multiclass(多クラス分類)
'metric': {'multi_error'}, # multi_error(正答率)でモデルを評価(metric)する
'num_class': 6, # クラスの数(設定値は1~6の6段階)
'learning_rate': 0.1, # 学習率(defaultの0.1に設定。)
'num_leaves': 31, # ノードの数(defaultの31に設定。)(余りに大きい値だと過学習してしまうらしい。)
'min_data_in_leaf': 1, # 各ノードの最小データ数(過学習を防ぐにはなるべく大きな値にした方が良いらしい。)
'num_iteration': 100} # 作成する木の数(defaultの100に設定。)(基本はearly_stoppingを使うので適当で良いらしい。)
lgb_results = {} # 学習履歴を入れる箱を準備
model = lgb.train(params=params, # ハイパーパラメータをセット
train_set=lgb_train, # 訓練データを訓練用にセット
valid_sets=[lgb_train, lgb_test], # 訓練データとテストデータをセット
valid_names=['Train', 'Test'], # データセットの名前をそれぞれ設定
num_boost_round=100, # 計算回数
early_stopping_rounds=10, # early_stopping(学習成果が向上しなくなったら学習をやめる設定)
evals_result=lgb_results) # 学習履歴を準備した箱に保存
# ベストなモデルを取得
best_iteration = model.best_iteration
3.3. 学習結果で予測させる
最後に作成したモデルで予測を行います。
貼り付けたコードでは何行か記載していますが、実際に予測を行っているのは「y_pred = model.predict(X_test, num_iteration=model.best_iteration)」の部分だけで、残りの部分は結果の確認用のコードになっています。
import numpy as np
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
import matplotlib.pyplot as plt
# ベストなモデルでテストデータを予想
y_pred = model.predict(X_test, num_iteration=model.best_iteration)
y_pred_max = np.argmax(y_pred, axis=1)
# Confusion Matrixを生成
ConfusionMatrixDisplay(confusion_matrix(Y_test, y_pred_max)).plot()
# Confusion Matrixを表示
plt.show()
4. 今回作成したコード
ということで、これまでのコードをまとめるとこうなります。
# coding: UTF-8
import pandas as pd
from sklearn.model_selection import train_test_split
import lightgbm as lgb
import numpy as np
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
import matplotlib.pyplot as plt
# データベースファイルを読み込む
df = pd.read_csv("D:\Test/database.csv", encoding="shift-jis").fillna(0)
# 訓練データとテストデータに分割する(設定以外を使用して、設定を求める)
# set1=1番台の設定を求める。2番台~6番台の設定を求めたい場合はset2~set6に変更する。
X = df.drop(columns=['set1', 'set2', 'set3', 'set4', 'set5', 'set6'], inplace=False).values.astype('float')
y = df[['set1']].values.astype('float') - 1
# 普通にランダムにすると設定1のデータばかり集まる可能性があるので、stratifyで設定の割合を揃える。
X_train, X_test, Y_train, Y_test = train_test_split(X, y, test_size=0.2, random_state=0, stratify=y)
# データセットを登録
lgb_train = lgb.Dataset(X_train, Y_train)
lgb_test = lgb.Dataset(X_test, Y_test, reference=lgb_train)
# LightGBMのハイパーパラメータを設定
params = {'task': 'train', # train(学習) or predict(予測)
'boosting_type': 'gbdt', # GBDT(決定木の勾配ブースティング)
'objective': 'multiclass', # multiclass(多クラス分類)
'metric': {'multi_error'}, # multi_error(誤り率)でモデルを評価(metric)する
'num_class': 6, # クラスの数(設定値は1~6の6段階)
'learning_rate': 0.1, # 学習率(defaultの0.1に設定。)
'num_leaves': 31, # ノードの数(defaultの31に設定。)(余りに大きい値だと過学習してしまうらしい。)
'min_data_in_leaf': 1, # 各ノードの最小データ数(過学習を防ぐにはなるべく大きな値にした方が良いらしい。)
'num_iteration': 100} # 作成する木の数(defaultの100に設定。)(基本はearly_stoppingを使うので適当で良いらしい。)
lgb_results = {} # 学習履歴を入れる箱を準備
model = lgb.train(params=params, # ハイパーパラメータをセット
train_set=lgb_train, # 訓練データを訓練用にセット
valid_sets=[lgb_train, lgb_test], # 訓練データとテストデータをセット
valid_names=['Train', 'Test'], # データセットの名前をそれぞれ設定
num_boost_round=100, # 計算回数
early_stopping_rounds=10, # early_stopping(学習成果が向上しなくなったら学習をやめる設定)
evals_result=lgb_results) # 学習履歴を準備した箱に保存
# ベストなモデルを取得
best_iteration = model.best_iteration
# ベストなモデルでテストデータを予想
y_pred = model.predict(X_test, num_iteration=model.best_iteration)
y_pred_max = np.argmax(y_pred, axis=1)
# Confusion Matrixを生成
ConfusionMatrixDisplay(confusion_matrix(Y_test, y_pred_max)).plot()
# Confusion Matrixを表示
plt.show()
5. 結果の確認
では、結果を確認していきましょう。
実際に動かしていただくとわかると思いますが、こんなグラフ(表?)が表示されると思います。

これは「Confusion Matrix(混合行列)」と呼ばれる見せ方で、分類結果を確認するときにはよく使われます。
というのも分類結果を確認する際にこの表を見ると色んなことがわかるからです。
中でも個人的に重要だと思う2つの指標に関して、以下に記載します。
(1) Accuracy(正確度、正答率)
これが一番イメージしやすいと思います。
簡単にいうと、何問中何問正解だったか?という指標です。
例えば、「100台設定推測して、90台正解しました!」って言われたら、「設定推測よくできてる!」って思いますよね。
ただ、Accuracyだけを見てると落とし穴にはまることがあります。
それを防ぐための指標が次に説明するPrecisionです。
(2) Precision(精度)
先ほど例に出した、「100台設定推測して、90台正解しました!」って言われたとき、こんな疑問がわきませんか?
「とりあえず設定1って答えとけばだいたい正解するんじゃない?」って。
その通りです。例えば、「100台中90台が設定1、10台が設定6」のホールがあったとして、とりあえず設定1って答えとけば90台正解しますよね?
けど、それって求めてるものと何か違ってて、「設定1を設定1と見極められたか?設定6を設定6と見極められたか?」も知りたいですよね。
そこでPrecisionでは、「設定6(or1)と予想した台のうち、何台が実際に設定6(or1)だったか?」を確認します。
ということで、見たい指標がわかったので、じゃあ一体さっきのグラフ上でどこを見れば良いのか?を説明します。
とりあえずぱっとわかるように、↓図の中に計算式を書いてみました。
落ち着いて考えれば、「まあそうなるよね。」って感じの式ですね。
Accuracyは「何問中何問正解だったか?」という指標だったので、正解した数を母数で割ればOK。
Pricisionは「設定6(or1)と予想した台のうち、何台が実際に設定6(or1)だったか?」という指標だったので、各設定値毎に正解した数を母数で割ればOK。
となります。

つまり、今回は全問正解!!
といってもこのままじゃ全然使えるわけもなく。
とりあえず最低限の使い方は説明できたと思いますので、こんな課題があるよねってのを備忘録をかねてリストアップしておきつつ終わりにしたいと思います。
(1) 設定値どうする?
そもそも私達は設定を知ることができません。
なので、差枚数を使うとか、出率を使うとか、プラスの台とマイナスの台でわけるとか、やらないとだめです。
当然その分予測制度は下がりますが、致し方なし。
(2) 特徴量どうする?
世の中にはいろいろな台の狙い方があります。
上げ狙い、下げ狙い、据え置き狙い、角台に入る、並びで入る、全台系、メイン機種が強いとかとか。
そのあたりをどうやって数値化して特徴量とするかっていうのが予測精度向上には重要です。
(3) データの収集どうする?
当然ながら今日のデータだけ見て明日のデータは予測できません。
ある程度のデータの母数が必要ですが、どのように集めるのかという問題はあります。
幸い最近は、お店のデータをまとめてくれているサイトや、ホール自らデータを公開してくれてたりするので、それを活用するのはありですね。
データを自動収集するスクレイピングっていう技術を学ぶのもありだと思います。
(※スクレイピングをするときは各サイトの利用規約をしっかり確認しましょう。)

コメント
コメントを投稿