スランプグラフ画像の歪を補正する方法

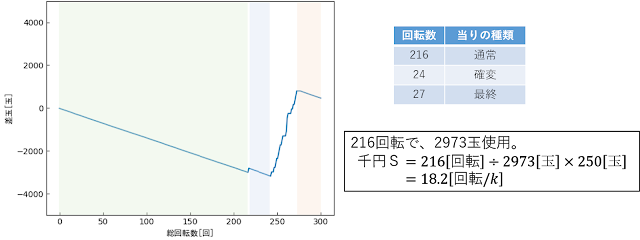
お世話になっております、スログラミングです。 今回はひさしぶりにpythonでプログラミングしようと思ってます。 遊技機の大型化。個人的にはエヴァとか牙狼みたいに動作するなら許せる派ですが、私の好みの話はどうでも良いので一旦おいておくとして、そういう機種でスランプグラフを撮ろうとすると、 こうなりません? この状態だと、 スランプグラフから千円Sを計算 したりするときにちょっとめんどくさかったりします。 (そもそも目視でも見辛いですし。) そこで今回は、 斜めから撮影したスランプグラフを真っすぐに戻す方法 について説明したいと思います。 本日のアジェンダはこちら。 透視変換とは? 透視変換のプログラミング 今回作成したコード まとめ 1. 透視変換とは? 目次で答えが先バレしちゃってますが、斜めから撮影したスランプグラフを真っすぐに戻すには、 透視変換 を使います。 射影変換というのもあるらしいですが、違いはよくわかってません。 そこら辺の説明は頭の良い方にお任せするとして、斜めに撮った状態のまま千円Sを算出するとどうなってしまうかを考えてみましょう。 他にも方法はあるかもしれませんが、 基本的には1pixあたりの出玉数を計算することで、千円Sを算出 すると思います。 例えば、冒頭で貼り付けた画像の場合、グラフの左端は0~10000玉までのサイズが522pixなのに対して、右端は384pixとなっています。 この場合、1pixあたりの出玉数は、 ・左端:10000[玉] / 522[pix] = 19.16[玉/pix] ・右端:10000[玉] / 384[pix] = 26.04[玉/pix] となるので、 左端で求めた1pixあたりの出玉数を使って、右端の出玉数を算出したりするとおかしな値となってしまい ます。 (1pixあたり5玉ずつずれていく。) 左端の出玉数は左端で求めた1pixあたりの出玉数を使って、右端の出玉数は右端で求めた1pixあたりの出玉数を使う、とか